SQLite is Enough
For simplicity I stick with SQLite where possible for the projects I post here. It is very straightforward compared to postgresql (which I use a lot in my job) because database setup basically just becomes part of coding an api. The result is that I have one less thing to worry about and can keep these enjoyable. Db backups are as simple as streaming the .backup file from SQLite to another server over ssh.
I wanted to get a sense of how far using SQLite as a database on a reasonably powered server could take me in terms of scale, so I set up some simple benchmarking.
The Setup
I built two identical APIs, one in python using FastAPI and one in Rust using Axum. Each is set up to respond to requests that either initiate reads and writes to an SQLite database. The table's primary key is used in each read request. Both APIs use the same concurrency pattern: all writes are funneled through a single dedicated writer thread, while reads run in parallel. WAL mode is enabled, so readers never block the writer and vice versa.
A "load generator" using a configurable number of concurrent async workers, written in Rust using reqwest + tokio, starts by warming up the db with 1000 entries, and then proceeds to hammer the API with both get requests to retrieve data and post requests to write a new entry into the db. The mix is 90% reads / 10% writes, a rough but I think fair estimation for many web apps. All payloads are 2 KB. While running, the load generator gathers statistics on the time requests take to complete.
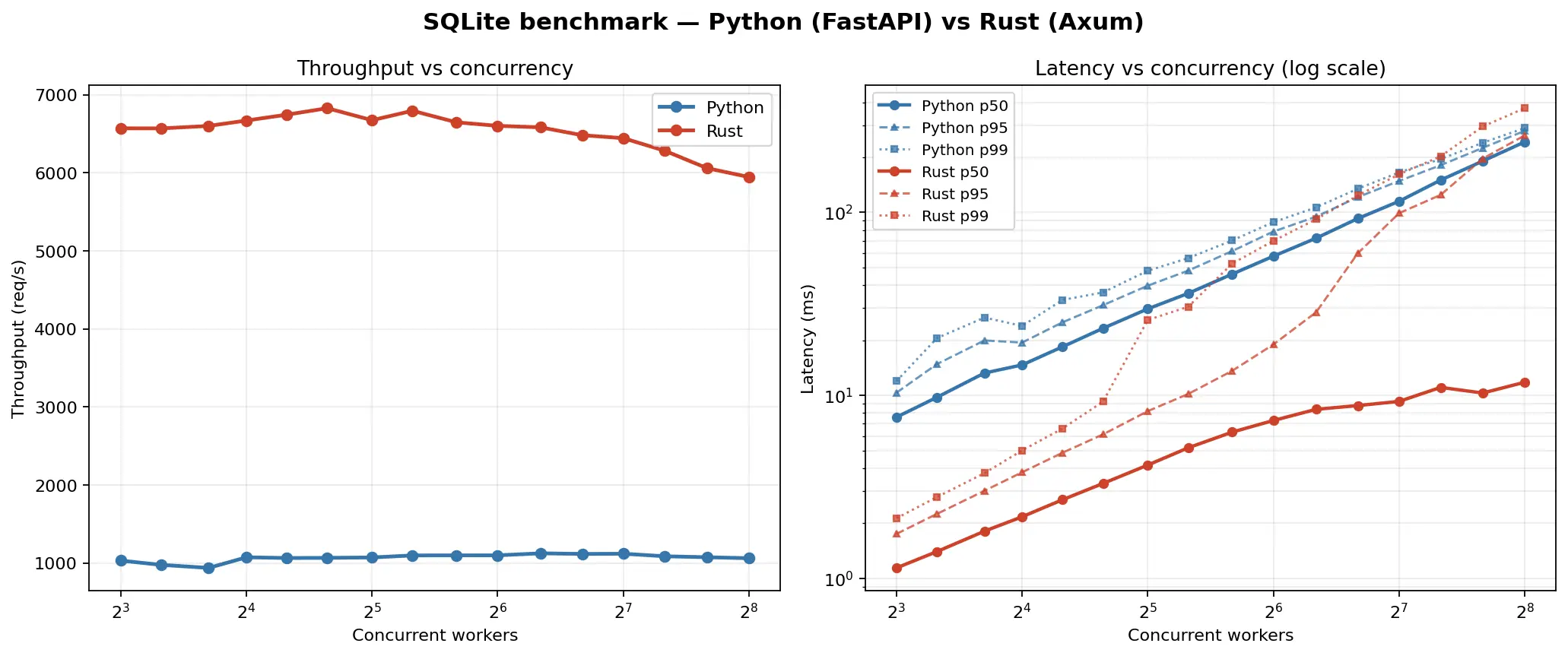
To gather useful data I configured the load generator tool to run with (8, 32, 64, 128, 256) workers, sending 50,000 requests at each level. This allows finding the point where the api can no longer handle the load. The server process was pinned to 4 CPU cores and the load generator to the remaining 16 so the two didn't fight for compute.
Methodology
This setup is specific to the use case I want to test. To test the raw performance of SQLite in Rust vs Python, no HTTP api would be involved, however this setup represents my needs by showing me the performance of APIs + SQLite. I ran these tests on my laptop (ThinkPad P15v in power saving mode) to represent a capacity that would be easy to scale to by increasing the specs of the server in the cloud where the applications run.
Results
Python (FastAPI + sqlite3):
| workers | rps | p50 (ms) | p95 (ms) | p99 (ms) | errors |
|---|---|---|---|---|---|
| 8 | 977 | 7.99 | 11.25 | 13.32 | 0 |
| 32 | 1,030 | 30.84 | 42.80 | 50.94 | 0 |
| 64 | 1,096 | 58.03 | 78.68 | 88.49 | 0 |
| 128 | 1,107 | 115.85 | 155.13 | 171.52 | 0 |
| 256 | 978 | 258.11 | 320.22 | 348.16 | 0 |
Rust (Axum + rusqlite):
| workers | rps | p50 (ms) | p95 (ms) | p99 (ms) | errors |
|---|---|---|---|---|---|
| 8 | 6,393 | 1.17 | 1.81 | 2.18 | 0 |
| 32 | 6,680 | 4.33 | 8.26 | 21.70 | 0 |
| 64 | 6,528 | 7.75 | 18.79 | 66.82 | 0 |
| 128 | 6,197 | 9.85 | 101.72 | 170.12 | 0 |
| 256 | 5,939 | 10.54 | 304.29 | 394.12 | 0 |
This means that the median request completed in 7.99 ms for the Python server and 1.17 ms for the Rust server. Overall the Rust implementation was over 6 times faster despite the fact that the amount of processing required on the request body was minimal.
The similarities in the p99 results between the Python and Rust implementations for higher worker counts suggest where the writes to the database become the limiting factor in the performance of the API.
More to the point, both the Python and Rust implementations of the system were far more than sufficient for my needs.
If the average user sends a request every 10 seconds while using a web application, then a single (admittedly fairly powerful) server could handle ~11,000 active users with the Python implementation or ~66,000 active users with the Rust implementation.
This doesn't account for spikes in traffic but it is still such a large threshold that I am confident to keep doing what I am doing.
Caveats / Conclusion
Admittedly, this setup is in the ideal scenario. I did not test anything external to the backend examples, nor did I include a simulation of more complex processing that needs to happen to the data before inserting or sending. I'd also like to build out more complete tests in the future, like more complex database schemas, serving large amounts of static content, and websocket based workloads.
In the future I might cover how to scale a SQLite setup like this to multiple servers with read replicas of the database.
But, for now this is sufficient to make me confident to continue launching projects this way, and much more intrinsically satisfying than paying a middleman or maintaining a postgres database myself for hobby projects.
note:
To get data for the cover image, I ran the same system with [8, 10, 13, 16, 20, 25, 32, 40, 51, 64, 81, 102, 128, 161, 203, 256] workers.
another note:
code is here.